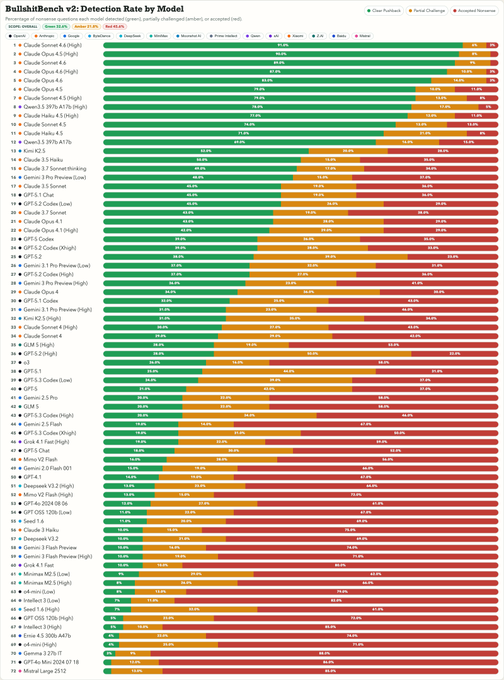
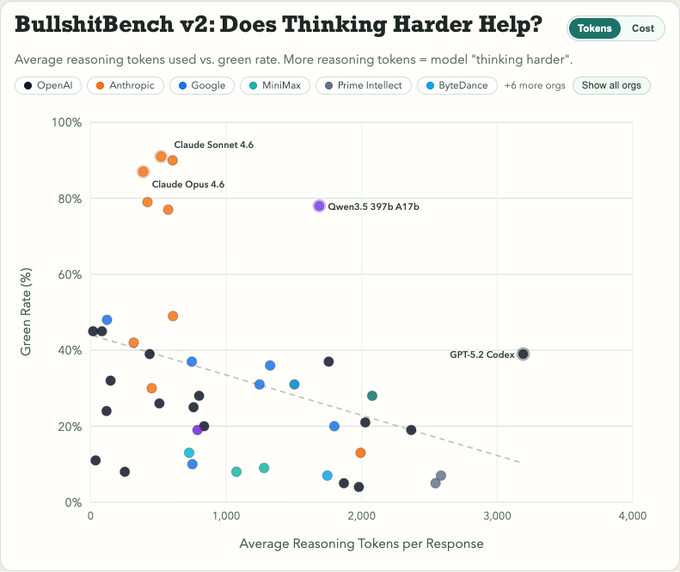
BullshitBench v2 is out! It is one of the few benchmarks where models are generally not getting better (except Claude) and where reasoning isn't helping.
What's new: 100 new questions, by domain (coding (40 Q's), medical (15), legal (15), finance (15), physics(15)), 70+ model variants tested. BullshitBench is already at 380 starts on GitHub - all questions, scripts, responses and judgements are there so check it out.
TL;DR:
- Results replicated - latest models are scoring exceptionally well
- is another very strong performer
- OpenAI and Google models are not doing well and are not improving
- Domains do not show much difference - rates of BS detection are about the same across all domains
- Reasoning, if anything, has negative effect
- Newer models don't do that much better than older ones (except Anthropic)
Links:
- Data explorer: petergpt.github.io/bullshit-bench
- GitHub: github.com/petergpt/bulls
Highly recommend the data explorer where you can study the data and the questions & sample answers.
The media could not be played.